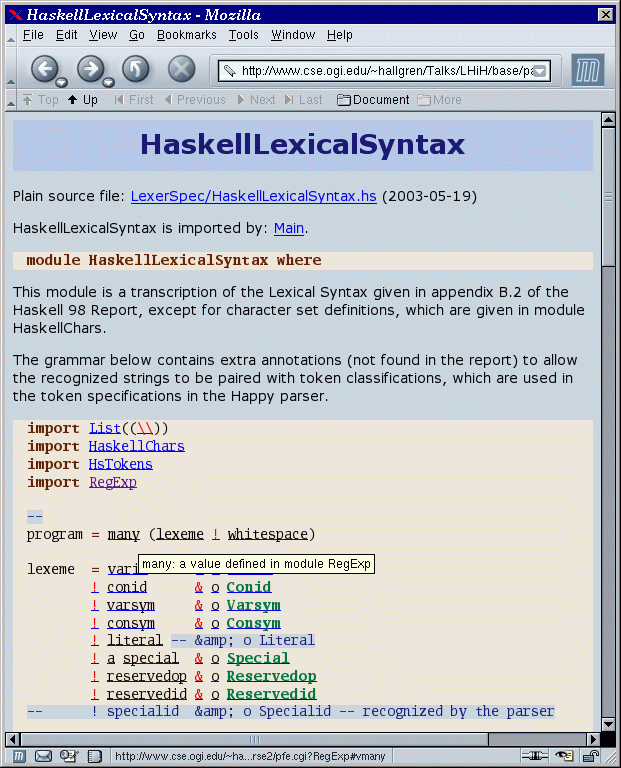
hs2html A sample Haskell module
rendered as HTML by the Programatica Tools.
Thomas Hallgren James Hook Mark P. Jones
Richard B. Kieburtz
OGI School of Science & Engineering
Oregon Health & Science University
20000 NW Walker Rd, Beaverton, Oregon, USA
http://www.cse.ogi.edu/PacSoft/projects/programatica/
Industry and academia have attacked this problem in many different ways, demonstrating concretely that the use of techniques such as systematic design processes, rigorous testing, or formal methods can each contribute significantly to increased reliability, security, and trustworthiness. There are obviously some significant differences between these techniques, but there is also a unifying feature: each one results in some tangible form of evidence that provides a basis for trust. Examples of such evidence include a record of the meeting where a code review was conducted, the set of test cases to which an application was subjected, or a formal proof that establishes the validity of a critical property.
Unfortunately, the diversity, volume, and variability of evidence that is needed in practice, even in the development of some fairly small systems, makes it hard to manage, maintain, and exploit this evidence as a project evolves and as meaningful levels of assurance are required. Without support, practical difficulties like these could easily discourage or prevent system builders from capturing and leveraging evidence to produce systems in which they, and their users, can develop a well-placed trust.
In the Programatica project at OGI [high-assurance], we are exploring the role that tools can play in facilitating and supporting effective use of evidence during the design, development and maintenance of complex software systems. From a programmer's perspective, Programatica provides a development environment for an extended version of the functional programming language Haskell [Haskell98revised] that provides a notation (and an associated logic, called P-logic [plogic]) for expressing properties of Haskell code. From a verification perspective, we expect that a broad spectrum of techniques will be useful in establishing such properties, including code review, testing, and formal methods. To support evidence management, Programatica provides: mechanisms for capturing different forms of evidence in certificates; methods exploiting fine-grained dependency analysis to automate the tasks of tracking, maintaining, and reestablishing evidence as a system evolves; and tools to help users understand, manage, and guide further development and validation efforts. One way to understand Programatica is as a framework for Extreme Formal Methods: we expect property assertions to be developed and established in parallel with the code that they document, just as test cases are developed in extreme programming [Beck:extreme].
This paper describes the current version of the Programatica tools and illustrates how they address some of the above goals in practice. The tools, while still a work in progress, can already manipulate Haskell programs in various ways and have some support for evidence management. In Section tools, we describe some of the features that the tools provide to support program development in Haskell, including facilities for browsing, slicing, and generating coding metrics. Section sec-evman describes functionality that is more directly targeted at the needs of evidence management. Programatica is designed to provide an open architecture for interfacing with external tools, and we illustrate this by describing two different `server' components. The first, described in Section hs2alfa, connects Programatica programs and property assertions to Alfa, a proof editor for structured type theory. The second, described in Section plover, provides a corresponding connection between Programatica and Plover, an automatic verification engine for P-logic. Notes on the implementation are provided in Section implementation.
The tools operate on a project, which is simply a collection of files containing Haskell source code. The command pfe new creates a new project, while pfe add adds files and pfe remove removes files from a project. There is also a command pfe chase to search for source files containing needed modules. This is the only command that assumes a relationship between module names and file names. A wrapper script pfesetup uses pfe new and pfe chase to create a project in a way that mimics how you would compile a program with ghc --make [ghc] or load it in Hugs [hugs].
Like batch compilers, pfe caches various information in files between runs (e.g., type information). pfe also caches the module dependency graph, while other systems parse source files to rediscover it every time they are run. This allows pfe to detect if something has changed in a fraction of a second, even for projects that contain hundreds of modules.
Once a project has been set up, the user can use pfe for various types of queries. For example, pfe iface M displays the interface of module M, pfe find x lists modules that export something called x and pfe uses M.x lists all places that use the entity called x that is defined in Module M.
While the syntax highlighting provided by editors such as Emacs and Vim is based on a simple lexical analysis, our tool also makes use of syntax analysis to distinguish between type constructors and data constructors. Also, for hyperlinking identifiers to their definition, a full implementation of the module system and the scoping rules of Haskell are used. Although the source code is parsed, the HTML code is not generated by pretty-printing the abstract syntax tree, but by decorating the output from the first pass of our lexical analyzer [lhih-online], preserving layout and comments.
We also support a simple markup language for use in comments, keeping the plain ASCII presentation of source text readable, while, at the same time, making it possible to generate nice looking LaTeX and HTML from it. We used this system, for example, to prepare our paper on the Haskell Module System [haskellmodules].
Our HTML renderer is a tool for documenting and presenting source code, in contrast to Haddock [haddock], which is a tool for producing user documentation for libraries.
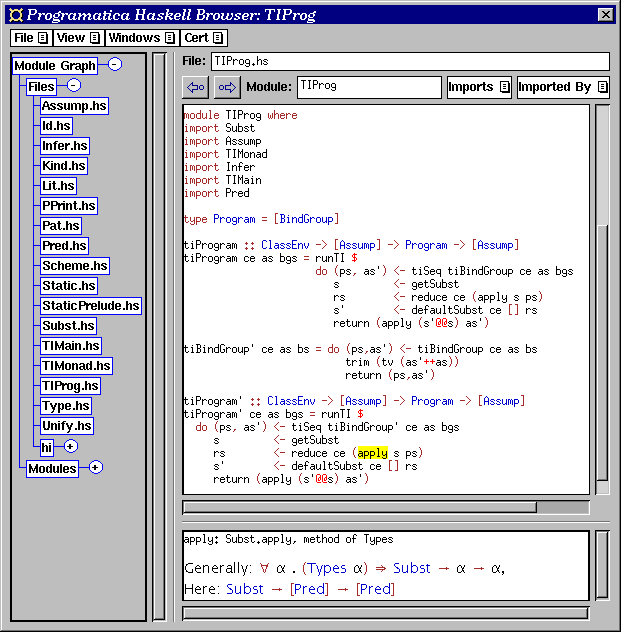
While HTML rendering makes it possible to use a standard web browser to browse Haskell programs, we have also implemented a dedicated Haskell browser (Figure pfebrowser). It assumes that a project has already been set up with pfe, and is started with the command pfebrowser. It provides a syntax highlighted and hyperlinked source view similar to the one provided in the HTML rendering, but it also has some additional functionality. For example, the user can click on an identifier to find out what its type is. The browser can reload and retypecheck a module after it has been edited. Information is cached internally to make this quick. Currently, reloading and retypechecking a moderately sized module (a few hundred lines or so), takes just a second or two.
At present, the tools type check complete modules, and do not provide any type information type checking fails. In the future, we might make the type checker more incremental, providing partial information in the presence of type errors. Other possible features for future development include turning the browser into a Haskell editor, and creating a dedicated proof tool for Haskell, perhaps similar to the Sparkle proof tool [sparkle] for Clean.
Viewing a program as a set of definitions, the slicer computes, given an identifier, the subset of the definitions that are referenced, directly or indirectly, from that identifier. For example, by slicing with Main.main as the starting point, you can remove dead code from a program. This functionality is provided by the command pfe slice M.x. The output is a set of valid Haskell modules that, for example, can be loaded in Hugs. (It will not be a complete Haskell program if slicing starts from something other than Main.main.)
Slicing is driven by a dependency analysis on type-checked code, allowing unused instance declarations to be eliminated. However, to keep the slicer simple, top-level declarations are treated as atomic units and this can make the slicing coarse, for example including definitions of default methods (and everything they depend on) in class declarations, even if they are not needed in any instance.
The slicer preserves the module structure of the source program. Import and export declarations are adjusted appropriately.
Because of the annoying monomorphism restriction, eliminating a definition that is not used can change the meaning of a declaration that is used. Dependencies caused by this side effect are currently not taken into account by our slicer.
Support for other forms of metrics might be added in the future.
At the moment, the command line tools and the browser support the creation and validation of certificates for the following basic forms of evidence:
There is work in progress on support for other forms of evidence, and our implementation has an extensible architecture to make it easy to plug them in using certificate servers to act as bridges between our code and external tools.
When source code is changed, the validity of existing certificates can be affected. Revalidating certificates might require some work by the user. To help identify those changes that can actually influence the validity of a certificate, dependencies are tracked on the definition level (rather than the module level). Changes are detected by comparing hash values computed from the abstract syntax. As a result, we avoid false alarms triggered by changes to irrelevant parts of a module, or by changes that only affect comments or the layout of code.
One of the main tasks of a certificate server is to translate P-logic property assertions and the corresponding parts of the program that they refer to into the language/notation of an external tool. (Slicing, as described in Section slicing, is particularly useful here because it can help to reduce the amount of code that must be translated.) The following sections describe how this is accomplished in building servers for Alfa (Section hs2alfa) and Plover (Section plover).
The translation to Structured Type Theory [stt] allows asserted properties to be proved formally in the proof editor Alfa [hallgren:alfa-homepage]. The translation is based on type checked code. Polymorphic functions are turned into functions with explicit type parameters and overloading is handled by the usual dictionary translation, turning class declarations into record type declarations and instance declarations into record value definitions.
The syntax of Structured Type Theory is simpler than that of Haskell, so a number of simplifying program transformations are performed as part of the translation. This affects, for example, list comprehensions, the do-notation, pattern matching, derived instances and literals. There are also various ad-hoc transformations to work around syntactic restrictions and limitations of the type checker used in Alfa. Apart from this, the translated code looks fairly similar to the original Haskell code. While Haskell has separate name spaces for types/classes, values and modules, Structured Type Theory has only one, so some name mangling is required to avoid name clashes. This is done in a context-independent way, so that when some Haskell code is modified, the translation of unmodified parts remains unchanged, allowing proofs about unmodified parts to be reused unchanged.
While type theory formally only deals with total functions over finite data structures, the translator allows any Haskell program to be translated. Alfa contains a syntactic termination checker [abel:foetus] that can verify that a set of structurally recursive function definitions are total. When the translation falls outside that set, any correctness proofs constructed in Alfa entail only partial correctness, and we leave it to the user to judge the value of such proofs. In the future, we might use a more sophisticated termination checker and/or change the translation to use domain predicates [bove:thesis] to make partiality explicit and to make the user responsible for providing termination proofs.
While the type system of plain Haskell 98 can be mapped in a straight-forward way to the predicative type system of Structured Type Theory, we foresee problems extending the translation to cover existential quantification in data types and perhaps also higher rank polymorphism.
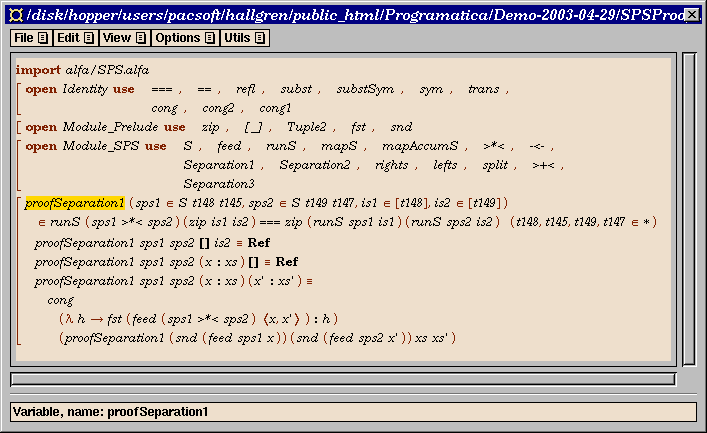
The source code in this example is a Haskell module SPS (see Figure SPS), defining synchronous stream processors and asserting a simple separation property for parallel composition of synchronous stream processors. (c.f., [high-assurance])
-- Synchronous stream processors
module SPS where
newtype S i o = S (i->(o,S i o))
feed (S sps) i = sps i
runS _ [] = []
runS sps (i:is) = continue (feed sps i) is
continue c is = fst c:runS (snd c) is
(>*<) :: S i1 o1 -> S i2 o2 -> S (i1,i2) (o1,o2)
sps1 >*< sps2 = S sps
where
sps (i1,i2) = ((fst o1,fst o2),snd o1>*<snd o2)
where o1 = feed sps1 i1
o2 = feed sps2 i2
assert Separation1 = {-#cert:Separation1#-}
All sps1 . All sps2 . All is1 . All is2 .
{runS (sps1>*<sps2) (zip is1 is2)} === {zip (runS sps1 is1) (runS sps2 is2)}
The first step in applying the Programatica tools is to set up a project using pfesetup:
Next, we can start pfebrowser and take a look at the Haskell code for module SPS, noting in particular the following definitions,pfesetup SPS.hs
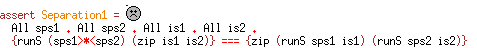
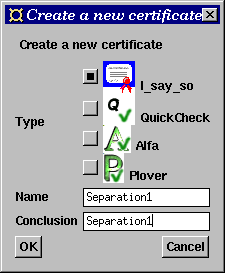
The Alfa translation is put in the subdirectory alfa/ and the proof template file created is called SPSProofs.alfa. (The Alfa certificate server currently suggests one proof file per Haskell module. The user can provide alternative file names, if desired.)
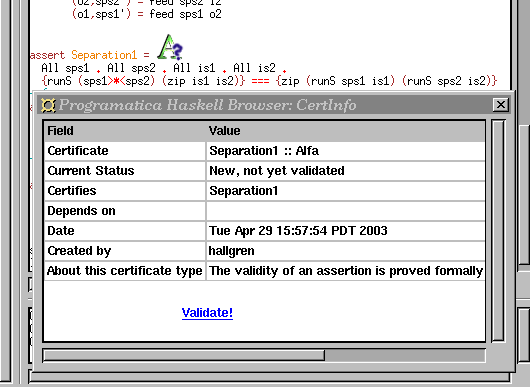
We should now proceed to edit the proof in the proof file, and eventually end up with a complete proof of the asserted property (Figure fig-proof). We should also run the termination checker in Alfa to verify that the proof was defined by structural induction rather than some meaningless circular construction. With a complete proof, we can rerun the validation command and find that it now succeeds and that the certificate icon is changed accordingly.
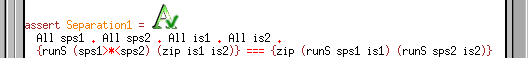
This certificate will remain valid so long as the user does not modify the definition of the property or of the functions on which it depends. If if there are any changes, however, it may be possible to revalidate the certificate automatically by rerunning the proof in SPSProofs.alfa.
Plover is an automatic verification server for Programatica. Given a Haskell program embedding one or more assertions expressed formally in P-logic, Plover attempts to find a proof of a designated assertion using (1) proof rules of the logic, (2) a few simple decision procedures for systems of equalities and linear inequalities, (3) a set of reduction rules for Haskell, and (4) strategies for applying these rules and decision procedures to sequent formulas in order to discharge proof obligations. Plover conducts its proof search without user interaction and it reports only its success or its failure; it does not construct a proof tree.
Plover implements P-logic directly. It does not depend upon a translation of Haskell into a simpler functional language nor does it translate formulas of P-logic into more primitive formulas. Nothing is ``lost in translation.''
The motivation to develop an automatic verification server lies in the boring nature of verification proofs. Unlike proofs of interesting mathematical theorems, many of which are based upon deep insights into the underlying mathematical structures, and which, once done, become the subject of continued study and improvement, verification proofs tend to be based upon shallow theories of superficially complex structures. Such proofs may not require deep insight, although they are often highly detailed. A verification proof itself is rarely the subject of ongoing study and improvement; it is the program whose properties are to be verified that is the object of primary interest. And in consequence, as a program evolves over time, the verification task is never completely finished. Proofs of a program's properties are inevitably made obsolete by its evolution and must be redone. Each of these considerations argues strongly for some degree of automation of verification proofs.
Of course, Plover, like any automated procedure that searches for proofs in a Turing-complete theory, is incomplete---its failure to find a proof does not mean that an assertion is false or even that it is unprovable. It only indicates that the strategies employed by Plover were insufficient to find a proof. In the current state of its implementation, there are many important aspects of Haskell 98 semantics for which Plover either implements no rules or lacks effective strategies. Plover does not currently support reasoning about monadic computations; it has no rules for derived operators; it lacks either decision procedures or axiomatic rules for even simple linear arithmetic; and it lacks effective strategies for verifying properties of case expressions. Rules for verifying properties of recursively-defined computations or recursive types have not yet been implemented. It does not yet comprehend data declarations.
Nevertheless, Plover is able to verify some interesting properties of programs defined using conditional expressions, tuples, non-recursive data types, function application and explicit abstraction. It comprehends (non-recursive) definitions including property definitions in P-logic.
Rules of P-logic are expressed in a sequent-calculus style, which supports the introduction of propositions either on the right or on the left of the turnstile in the consequent of a rule. While this style of presentation is perhaps less intuitive to the human than is natural-deduction style, with a duality between introduction and elimination rules for each form of object-language term, it allows greater flexibility in the design of an automated verifier.
Plover is implemented in Stratego, a higher-order strategy programming language. In Stratego, strategies are first-class entities, just as functions are in Haskell. This aspect of Stratego, together with a powerful library of strategies for manipulating basic term structures, for memoization, and for tasks such as capture-avoiding substitution in a lexically-scoped object term language, make it an excellent vehicle for implementing a theorem prover.
Stratego itself is implemented on a run-time library of routines for manipulating terms with maximal sharing; this gives it greater efficiency than would be gotten by building an implementation directly in a functional language such as Standard ML or Haskell.
The easiest way to invoke Plover from the Programatica tools environment is to create a certificate that names a property assertion embedded in a Programatica module, declaring the certificate to have the Plover type. This will indicate to the tool suite that Plover should be invoked when the certificate is to be validated. At that time, the Programatica tools will furnish as data the slice of the Programatica code on which the assertion depends (Section slicing). The whole sequence of linked operations needed to validate a certificate is launched by clicking the Validate button in the certificate information window displayed by the pfebrowser tool.
As a caveat, one must realize that Plover (like PVS and ACL2) is an ad hoc theorem prover. The strategies that it employs (including its encoding of logical inference rules) are simply computer programs, and they may contain errors. Potentially, greater assurance may be obtained from a principled theorem prover, such as Isabelle or Coq, that interprets proof rules in a strong type theory that accepts only sound reasoning steps. However, there is a price to be paid for stringent commitment to principle. It becomes impossible to take ``shortcuts'' in proof construction; every proof step must be justified by evidence.
Plover relies for its claim to sound reasoning upon external proof of the soundness of rules of P-logic, and upon rigorous testing to provide evidence that the Plover implementation has not compromised soundness by an unfortunate programming error. (Programming errors might also compromise completeness, but since that property is never claimed, this is not a fundamental problem.)
Our tools are implemented in Haskell, including the browser, which uses Fudgets [fudgets] for the user interface. Amongst other things, our implementation contains an abstract syntax; a lexer and a parser; a pretty printer; some static analyses, including inter-module name resolution; some program transformations; a type checker and definition-level dependency tracking.
Some parts---the abstract syntax, the parser and the pretty printer---were inherited from another source [hssource] and modified, while most other parts were written from scratch. Some parts---the lexer [lhih-online] and the module system [haskellmodules]---are implemented in pure Haskell 98 and can serve as reference implementations, while others make use of type system extensions, in particular multi-parameter classes with functional dependencies [jones:funcdep]. Together with a two-level approach to the abstract syntax [sheard01generic] and other design choices, this makes the code more modular and reusable, but perhaps also too complicated to serve as a reference implementation of Haskell.
The fact that the first pass of our lexer preserves white space and comments made it easy to implement the HTML renderer. The modular structure of the lexer also allowed us to quickly create a simple tool that someone asked for on the Haskell mailing list: a program that removes comments and blank lines from Haskell code [stripcomments].
While implemented from scratch, key design choices in the type checker were influenced by the simplicity of Typing Haskell in Haskell [jones99typing], the efficiency of the type checkers in HBC and NHC, and the constraint based approach used in one of Johan Nordlander's type checkers for O'Haskell [ohaskell]. It performs the dictionary translation and inserts enough type annotations to make the output suitable for translation to an explicitly typed language like Structured Type Theory or System F.